Site perso : Emmanuel Branlard
Next: B.2 Fortran source code | Up: B. Jacobi diagonalization of a symmetric matrix | Previous: B. Jacobi diagonalization of a symmetric matrix |
Navigation: Contents | Index
B.1 Mathematical description of the method
The method adopted by most algorithms to reduce a matrix A to a diagonal form is to apply a sequence of similarity transformations:So that eventually we have:
For the Jacobi method, these transformations consists of orthogonal similarities. Each Jacobi transformation, is a plane rotation designed to annihilate one of the off-diagonal matrix elements. Successive transformations undo previously set zeros, but the off-diagonal elements nevertheless get smaller and smaller, until the matrix can be considered diagonal for a given precision. Moreover the product of the transformations,
The basic Jacobi rotation ![]() is a matrix of the form
is a matrix of the form
![$\displaystyle P_{pq}= \left[ \begin{array}{ccccccc} 1 & & & & & &\\ &\dots & & ...
...s& & &\\ & & -s& &c & &\\ & & & & & \dots&\\ & & & & & &1\\ \end{array} \right]$](img754.gif) |
(B.4) |
The numbers ![]() and
and ![]() are the cosine and sine of a rotation angle
are the cosine and sine of a rotation angle ![]() :
:
| (B.5) |
The Jacobi rotation is used to transform matrix ![]() with the similarity:
with the similarity:
| (B.6) |
Now,
![]() changes only rows
changes only rows ![]() and
and ![]() of
of ![]() , while
, while
![]() changes only its columns
changes only its columns ![]() and
and ![]() . The result of the product on each side is, for
. The result of the product on each side is, for
![]() :
:
and otherwise:
Let's remember that we want to try to annihilate the off-diagonal elements. ![]() and
and ![]() are similar, so they have the same Frobenius norm
are similar, so they have the same Frobenius norm ![]() : the sum of squares of all components. However we can choose
: the sum of squares of all components. However we can choose ![]() such that
such that
![]() , in which case
, in which case ![]() has a larger sum of squares on the diagonal. As we will further see, this is important for the convergence of the method. In order to optimize this effect,
has a larger sum of squares on the diagonal. As we will further see, this is important for the convergence of the method. In order to optimize this effect, ![]() should be the largest off-diagonal component, called the pivot. From equation B.11,
should be the largest off-diagonal component, called the pivot. From equation B.11,
![]() yields:
yields:
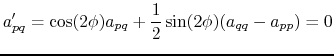 |
(B.12) |
from which we define
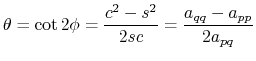 |
(B.13) |
If we let ![]() , the definition of
, the definition of ![]() can be rewritten
can be rewritten
| (B.14) |
We choose the smaller root of this equation, where the rotation angle is less than
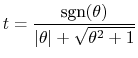 |
(B.15) |
If
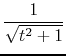 |
(B.16) | ||
| (B.17) |
To minimize numerical roundoff error, equation B.11 is replaced by
| (B.18) |
Similarly,
| (B.19) | |||
| (B.20) | |||
| (B.21) |
where
| (B.22) |
One can see the convergence of the Jacobi method by considering the sum of the squares of the off-diagonal elements:
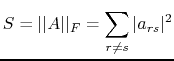 |
(B.23) |
Using equations B.7 - B.11 and the similarity properties, we have:
| (B.24) |
The sequence of S's thus decrease monotonically. Since the sequence is bounded below by zero, and since we can choose
| (B.25) |
where
| (B.26) |
the
Next: B.2 Fortran source code | Up: B. Jacobi diagonalization of a symmetric matrix | Previous: B. Jacobi diagonalization of a symmetric matrix |
Navigation: Contents Index